Mathematical Foundations and Architecture of Artificial Intelligence Systems
This section provides a structured explanation of the mathematics behind artificial intelligence, including neural networks, probability, optimization, and modern AI architectures such as transformers. It connects mathematical theory to real-world system behavior, enabling engineers and technical leaders to understand how AI models learn, scale, and perform.
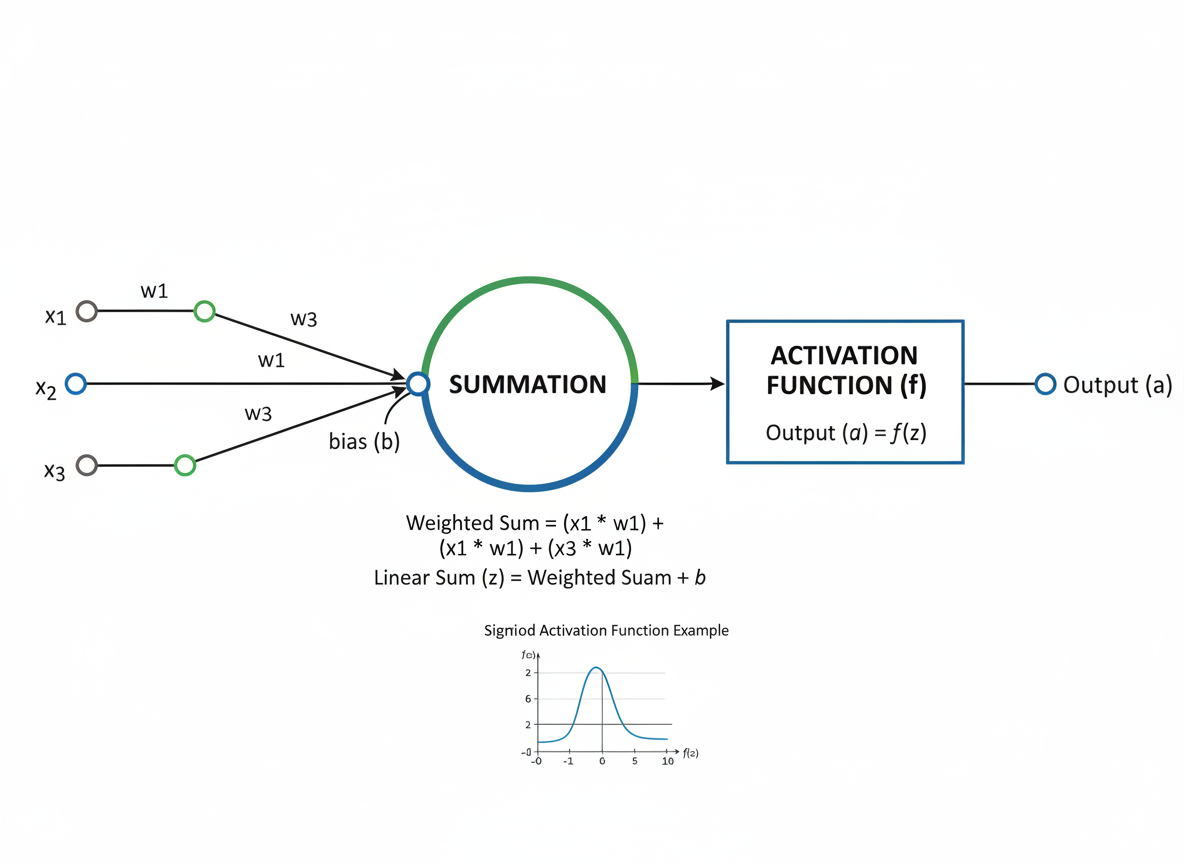
Figure B1. Neural Network Fundamentals in Artificial Intelligence
Neural networks are foundational mathematical structures used in artificial intelligence and machine learning. Each artificial neuron receives inputs, applies weights, adds a bias term, and passes the result through a nonlinear activation function. This process allows AI models to represent complex, non-linear relationships in data.
During the forward pass, information moves from input layers toward an output prediction. Learning occurs when the model adjusts its weights to reduce prediction error through optimization. Even relatively simple neural networks can approximate complex functions when supported by sufficient parameters, training data, and effective model design.
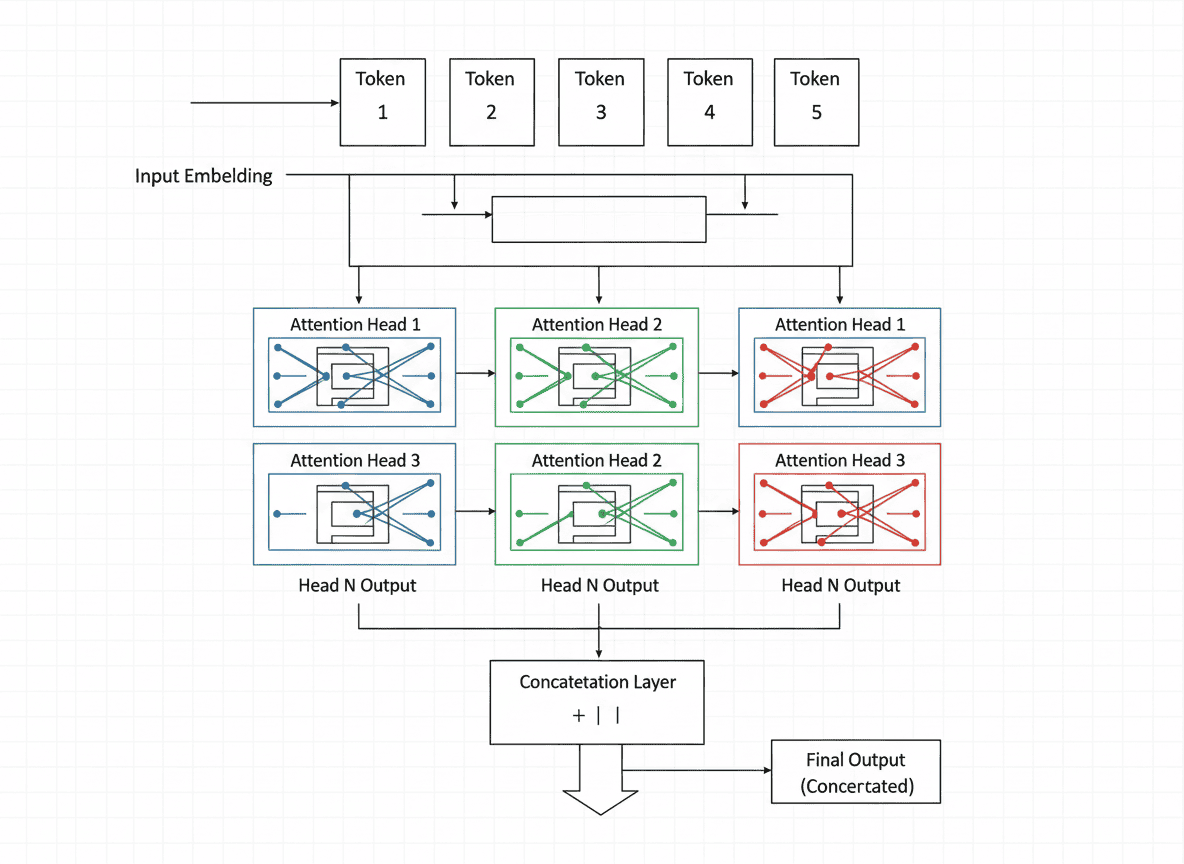
B3. Self-Attention Mathematics in Transformer Architecture and Machine Learning
Self-attention is a core mathematical mechanism in transformer architecture and modern artificial intelligence systems, including large language models. It enables each token in a sequence to evaluate relationships with all other tokens, allowing the model to capture context, semantic meaning, and dependencies across the entire input.
For an input matrix X, the model computes three learned projections: Queries Q, Keys K, and Values V. These components allow machine learning models to compare tokens, assign attention weights, and selectively integrate relevant information.
K = X W_K
V = X W_V
Attention scores are calculated using a scaled dot product and normalized with the softmax function:
The scaling factor √d_k improves numerical stability during training by preventing excessively large dot products as dimensionality increases. This results in a dynamic weighted combination of token representations, enabling contextual reasoning, long-range dependency modeling, and efficient information flow within deep learning models.
B3. Self-Attention Mathematics in Transformer Architecture
Self-attention is one of the core mathematical mechanisms behind transformer architecture and modern large language models. It allows each token in a sequence to compare itself with every other token and determine which relationships are most relevant for generating meaning, context, and prediction.
For an input matrix X, the model creates three learned projections: Queries Q, Keys K, and Values V. These projections allow the AI model to evaluate token relationships, assign attention weights, and pass forward the most relevant information.
K = X W_K
V = X W_V
Attention scores are computed using a scaled dot product and then normalized with softmax:
The scaling term √d_k helps stabilize training by preventing dot products from becoming too large as dimensionality increases. The result is a dynamic weighted mixing of information across tokens, enabling contextual reasoning, long-range dependency modeling, and flexible representation learning.
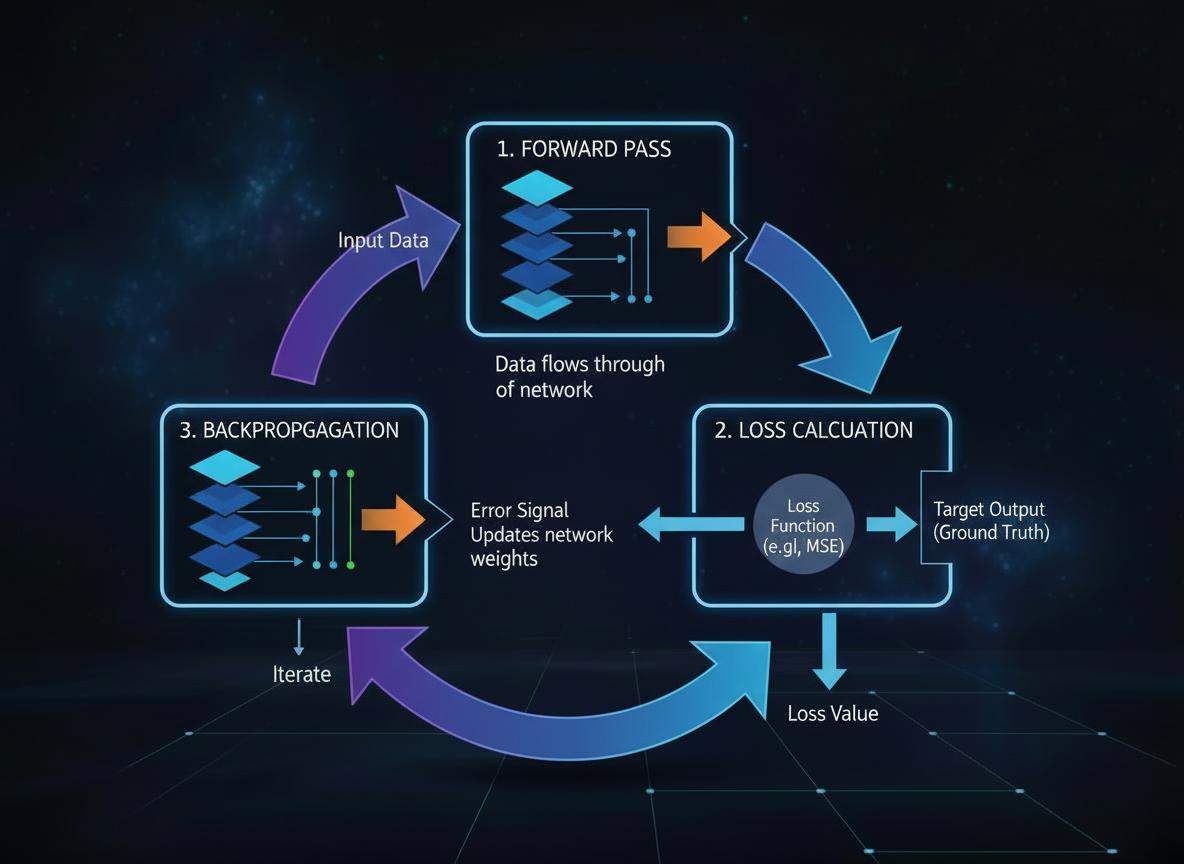
Figure B4. Loss Functions, Gradient Descent, and Optimization in Machine Learning
Loss functions are a core component of machine learning and artificial intelligence systems, quantifying prediction error by measuring the difference between model outputs and ground-truth targets. Neural networks are trained to minimize this loss through iterative optimization processes such as gradient descent.
Common loss functions include Mean Squared Error (MSE) for regression tasks and Cross-Entropy Loss for classification. The choice of loss function directly affects gradient behavior, convergence speed, stability, and overall model performance.
During training, gradients are propagated backward through the network using backpropagation, allowing model parameters to be updated in a direction that reduces error. This optimization process is fundamental to how deep learning models learn patterns, generalize to new data, and improve accuracy over time.
Figure B5. Transformer Feed-Forward Networks (FFN) in Deep Learning Models
In transformer architecture, the Feed-Forward Network (FFN) is a key component that processes each token independently after the self-attention mechanism. It consists of two linear transformations with a nonlinear activation function in between, expanding and then projecting feature representations within deep learning models.
While self-attention integrates contextual information across tokens, the FFN enhances model capacity by learning complex feature transformations at each position. This combination of attention and feed-forward processing enables transformer models, including large language models, to capture both relational structure and high-dimensional representations.
The FFN is typically combined with residual connections and layer normalization, improving training stability, gradient flow, and overall model performance in modern artificial intelligence systems.
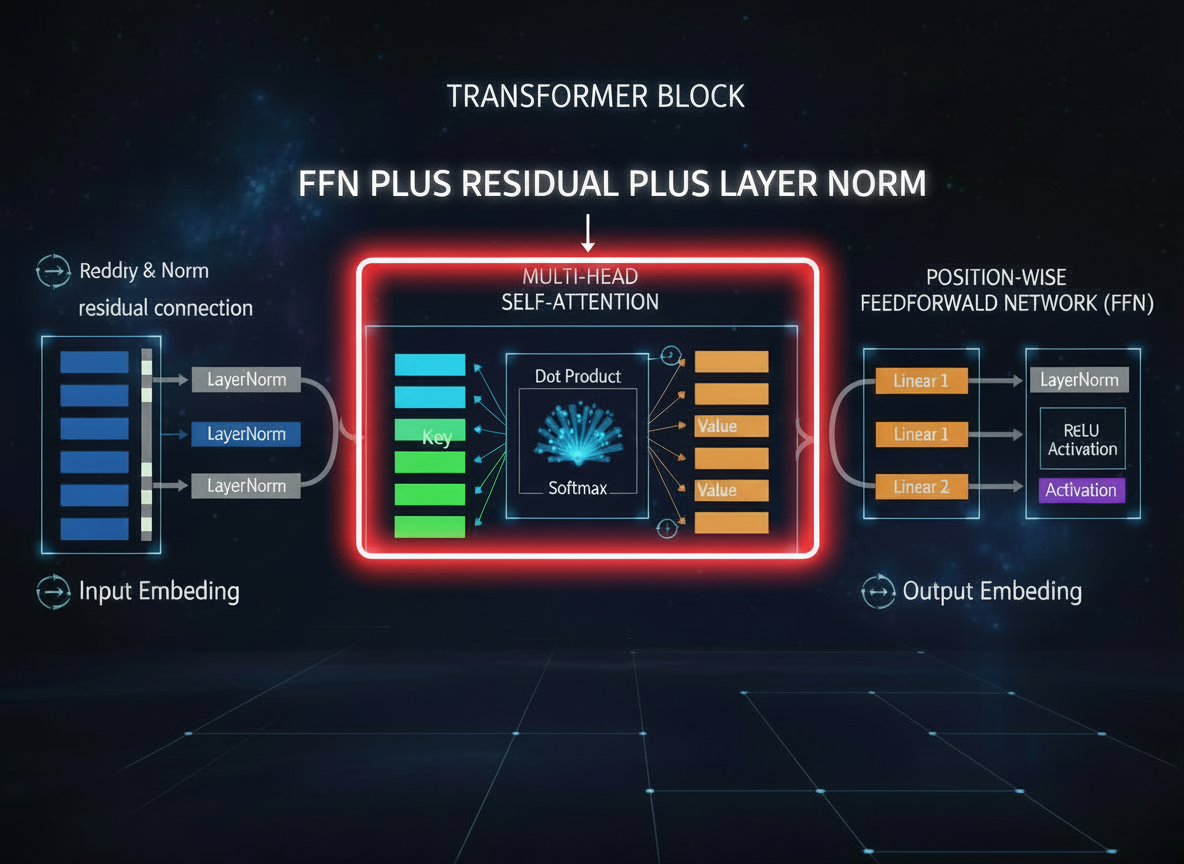
Figure B7. Softmax Temperature, Probability Distributions, and AI Model Output Control
Softmax is a mathematical function used in machine learning and artificial intelligence systems to convert model scores into probability distributions. In classification models and large language models, softmax helps determine which output is most likely based on learned patterns.
Temperature scaling adjusts how sharply or broadly probabilities are distributed. A lower temperature makes the model more deterministic by concentrating probability on the highest-scoring outputs, while a higher temperature produces a smoother distribution that increases variation and exploratory behavior.
Understanding softmax temperature is important for controlling AI model behavior, especially in generative AI systems where output reliability, creativity, consistency, and uncertainty all depend on how probabilities are shaped during inference.
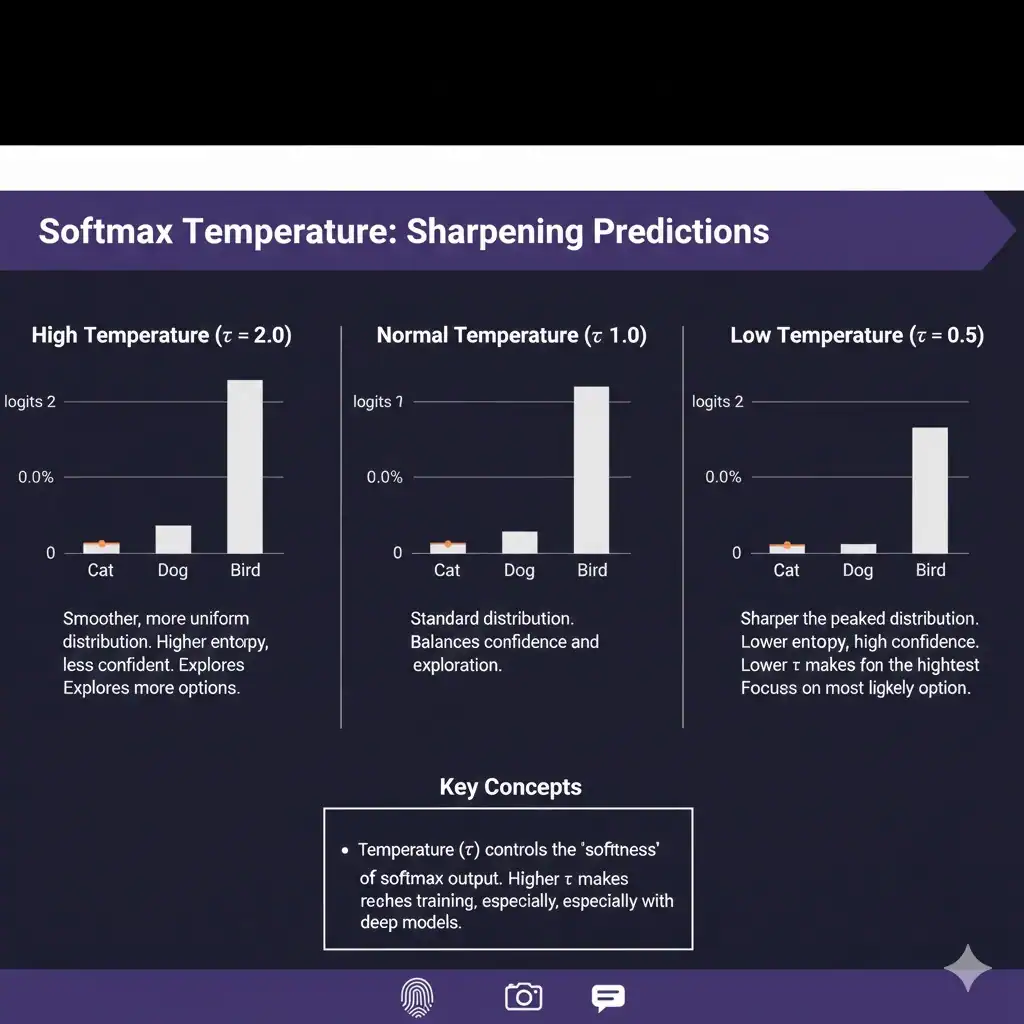
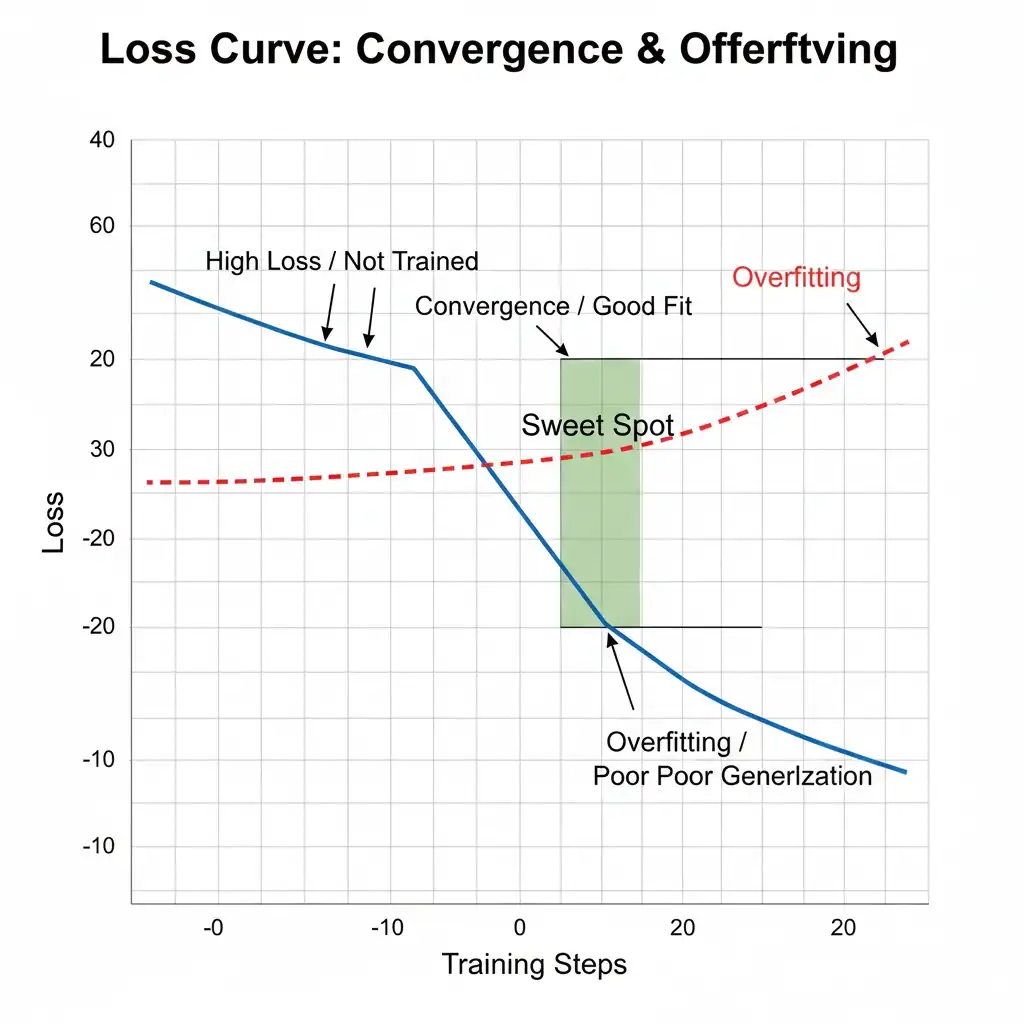
Figure B8. Training Objectives, Loss Curves, and Convergence in Machine Learning
Training a neural network involves minimizing an objective function, usually expressed through a loss function that measures prediction error. In artificial intelligence and machine learning systems, optimization algorithms such as gradient descent iteratively adjust model parameters to reduce loss across training steps or epochs.
Convergence occurs when loss values stabilize and the model approaches an effective solution. However, low training loss alone does not guarantee strong model performance. Comparing training loss with validation loss helps identify underfitting, overfitting, instability, and the point of optimal generalization.
This distinction is critical for real-world AI deployment because a model that performs well on training data may still fail on unseen data. Monitoring loss curves allows engineers to evaluate learning dynamics, improve model reliability, and select training strategies that support better generalization.
Figure B9. Backpropagation, Gradient Flow, and Learning in Neural Networks
Backpropagation is the fundamental learning algorithm used in neural networks and deep learning models. After a forward pass generates predictions, the model computes a loss function and propagates gradients backward through the computational graph using the chain rule of calculus.
These gradients show how each parameter contributes to prediction error, enabling optimization methods such as gradient descent to update weights and reduce loss. This iterative training process allows artificial intelligence systems to learn patterns, improve accuracy, and generalize to new data.
Stable gradient flow is essential for effective deep learning, especially in large neural networks where vanishing gradients, exploding gradients, or unstable updates can affect convergence, training reliability, and model performance.
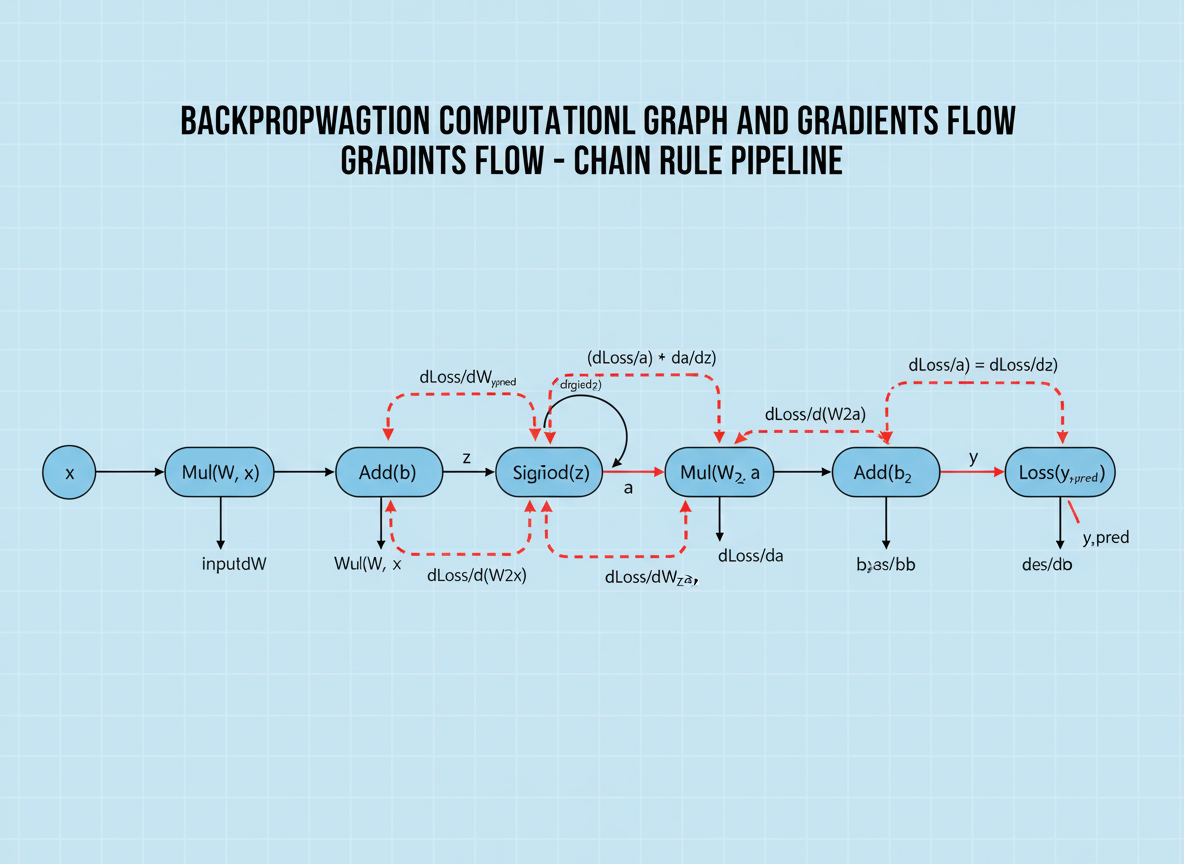
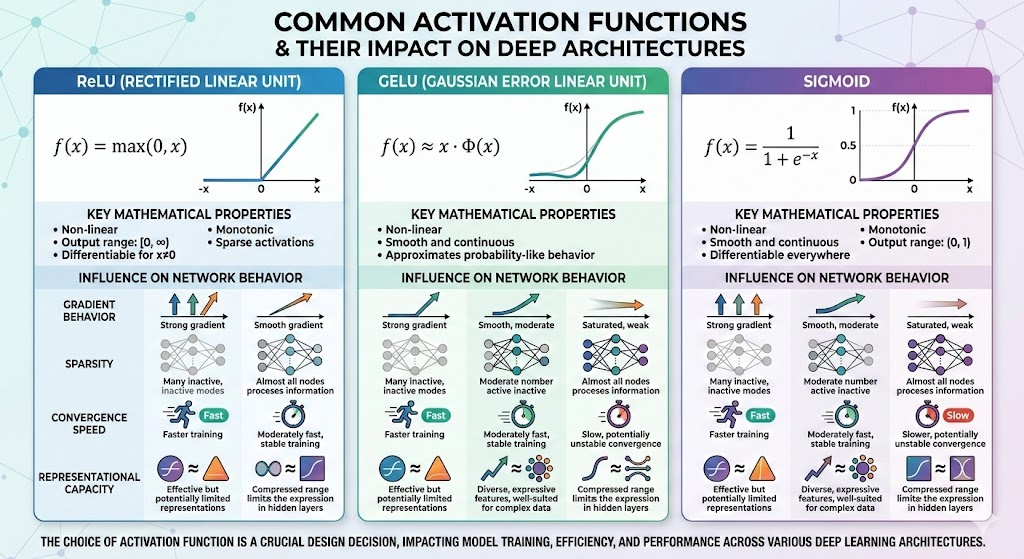
Figure B10. Activation Functions, Nonlinearity, and Model Expressivity in Neural Networks
Activation functions introduce nonlinearity into neural networks, enabling artificial intelligence systems to model complex patterns and relationships that cannot be captured through linear transformations alone. Without nonlinear activation functions, stacked neural network layers would collapse into a single linear model, severely limiting representational power.
Common activation functions used in deep learning include ReLU, GELU, Sigmoid, and Tanh. Each function influences gradient behavior, sparsity, convergence speed, and numerical stability during training, directly impacting model performance and optimization dynamics.
The choice of activation function plays a critical role in how neural networks learn hierarchical features, maintain stable gradient flow, and achieve high expressivity in modern machine learning architectures.
Figure B11. AI Alignment, Policy Layers, Runtime Guardrails, and Model Monitoring
AI alignment mechanisms help ensure artificial intelligence systems operate within defined behavioral, ethical, safety, and domain-specific boundaries. Techniques such as supervised fine-tuning, reinforcement learning from human feedback (RLHF), policy modeling, and evaluation frameworks shape how base models respond in real-world applications.
Runtime guardrails provide continuous oversight by enforcing constraints, filtering unsafe outputs, detecting policy violations, and monitoring model behavior during inference. These controls are especially important for large language models, generative AI systems, and enterprise AI deployments where accuracy, reliability, compliance, and user trust are critical.
Together, alignment layers, safety guardrails, and real-time monitoring reduce risks such as hallucination, unsafe recommendations, biased outputs, privacy exposure, and operational failure in production AI systems.

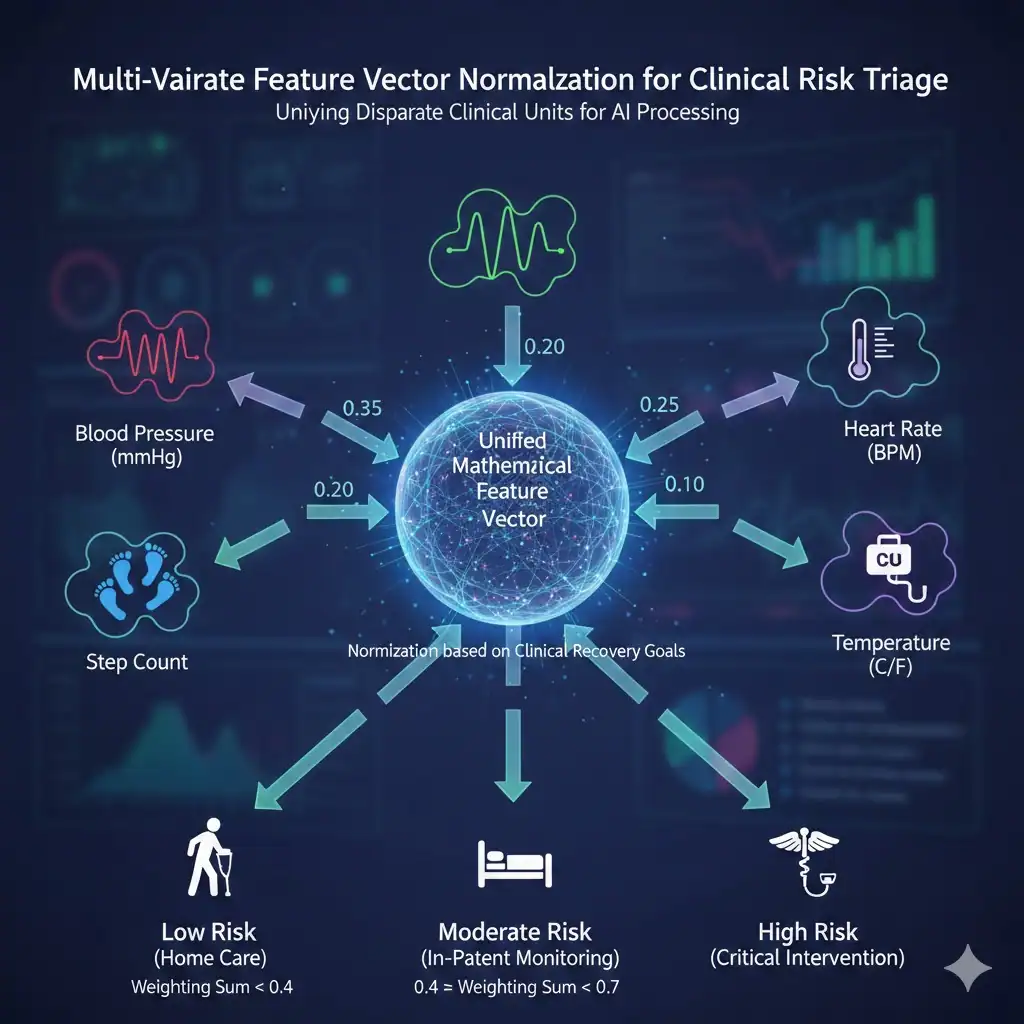
B12. Multivariate Feature Engineering and Normalization in Clinical AI Systems
Before artificial intelligence systems can process clinical data, heterogeneous variables such as blood pressure, heart rate, temperature, and activity levels must be normalized into a unified mathematical feature vector. This is a core function of feature engineering in machine learning and predictive healthcare analytics.
Normalization prevents any single variable from dominating model output due to scale differences, enabling proportional weighting based on clinical relevance, patient baseline, and recovery objectives. This improves predictive accuracy, risk stratification, and patient monitoring.
B13. Bayesian Inference, Probabilistic Modeling, and Uncertainty Quantification in AI
In real-world artificial intelligence systems, predictions must include uncertainty estimates. Bayesian inference and probabilistic modeling allow machine learning models to assign confidence levels, especially when wearable, sensor, or clinical data is noisy, incomplete, or inconsistent.
Uncertainty quantification is critical for safe AI deployment in healthcare. Clinicians rely on calibrated confidence scores to determine intervention thresholds, prioritize alerts, reduce false positives, and avoid unnecessary escalation of care.

B14. Knowledge Graphs, Contextual Reasoning, and Clinical AI Decision Support
Knowledge graphs provide structured relationships between clinical entities, enabling artificial intelligence systems to move beyond numerical prediction into contextual reasoning. By linking patient data to medical ontologies, symptoms, diagnoses, and treatment pathways, models gain interpretability and domain awareness.
This orchestration layer transforms statistical signals into clinically meaningful insights, connecting anomalies to comorbidities, contraindications, and evidence-based interventions. It supports advanced AI architectures such as retrieval-augmented generation, clinical decision support, and explainable AI systems.